Simulación y Entrenamiento
Entorno, MDP, arquitecturas neuronales y curvas de convergencia.
Entorno de Simulación
El entorno fue desarrollado en MATLAB/Simscape replicando la dinámica del prototipo físico. Los parámetros de masa, longitud e inercia se midieron directamente del hardware para garantizar fidelidad en la transferencia Sim-to-Real.
Proceso de Decisión de Markov (MDP)
| Elemento | Definición |
|---|---|
Estado s | \((\theta,\ \dot{\theta},\ x,\ \dot{x})\) |
Acción a | Fuerza discreta ∈ {−10, −9.5, …, +9.5, +10} N (41 acciones) |
Recompensa r | \(r_t = -(w_1\theta^2 + w_2\dot{\theta}^2 + w_3 u^2)\) |
| Límite de episodio | 600 pasos · θ fuera de ±160° termina el episodio |
| Factor de descuento | γ configurado en entrenamiento |
Curva de Entrenamiento — 4,000 Episodios
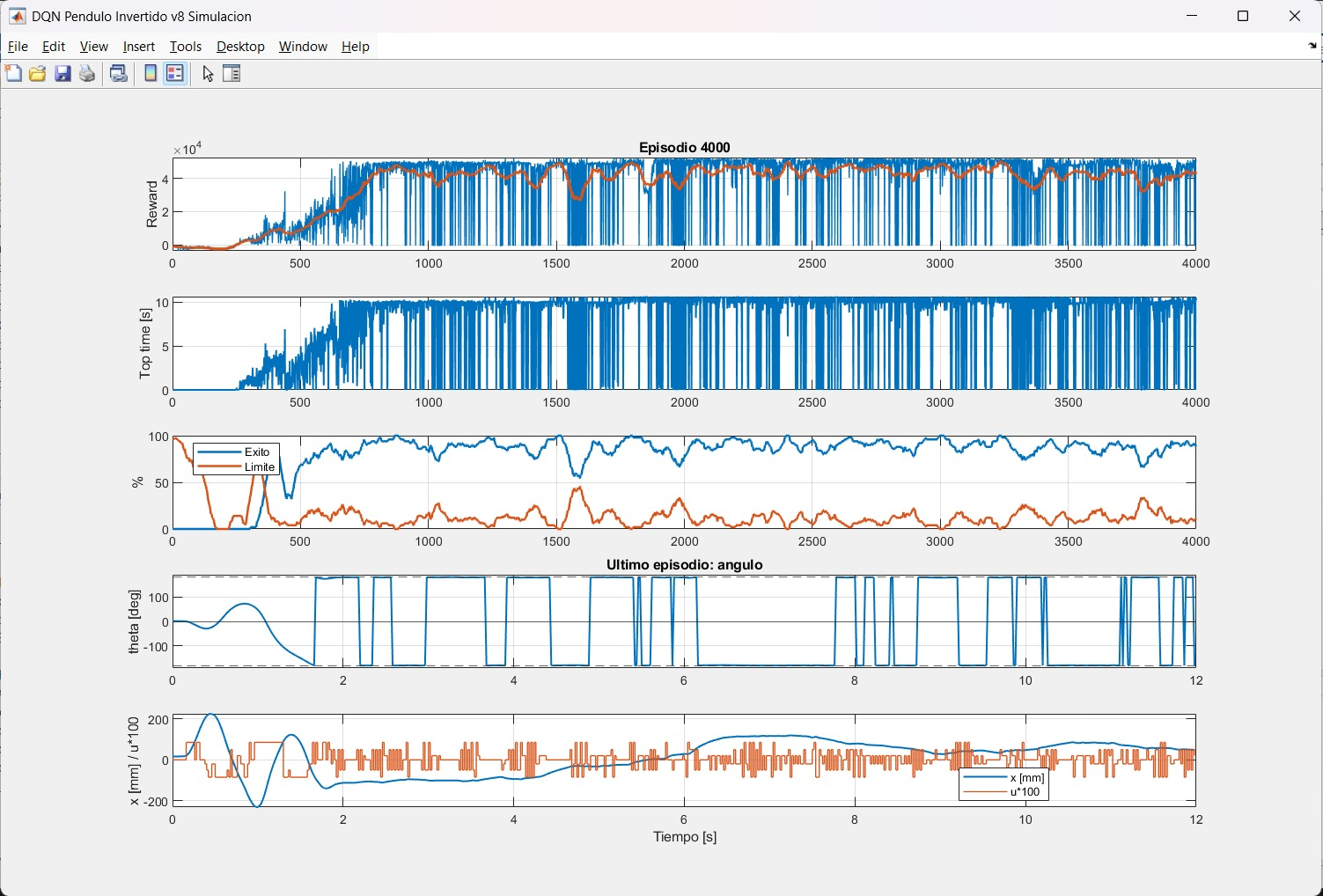
Evolución del entrenamiento: reward por episodio (promedio móvil en naranja), tiempo en equilibrio (top time), tasa de éxito vs. límite de posición, y comportamiento del ángulo y posición en el último episodio.
Resumen de los Últimos 50 Episodios

Métricas finales: reward medio 42,877.5, tasa de éxito 90 %, tiempo promedio en equilibrio 9.02 s.
Comparativa: Shallow Q-Learning vs. DQN
| Aspecto | Shallow Q-Learning (NNQ) | Deep Q-Learning (DQN) |
|---|---|---|
| Capas ocultas | 1 capa | 2 capas (64 × 64) |
| Activación | ReLU | ReLU |
| Optimizador | Básico | Adam |
| Salidas Q | 41 | 41 |
| Convergencia | Inestable / subóptima | Estable y óptima |
| Control resultante | Oscilatorio | Equilibrio sostenido |
La arquitectura profunda permitió al agente abstraer características robustas del entorno, logrando convergencia estable donde la red superficial fallaba.