Resultados
Métricas de entrenamiento, prueba greedy y desempeño en hardware real.
Tabla de Contenidos
- Entrenamiento — 4,000 Episodios
- Prueba de Política Greedy Final
- Análisis de las Gráficas
- Presentaciones
Entrenamiento — 4,000 Episodios
El agente DQN fue entrenado durante 4,000 episodios en el entorno de simulación Simscape. La curva de recompensa muestra convergencia clara a partir del episodio ~500, con alta varianza inicial típica de la exploración ε-greedy.
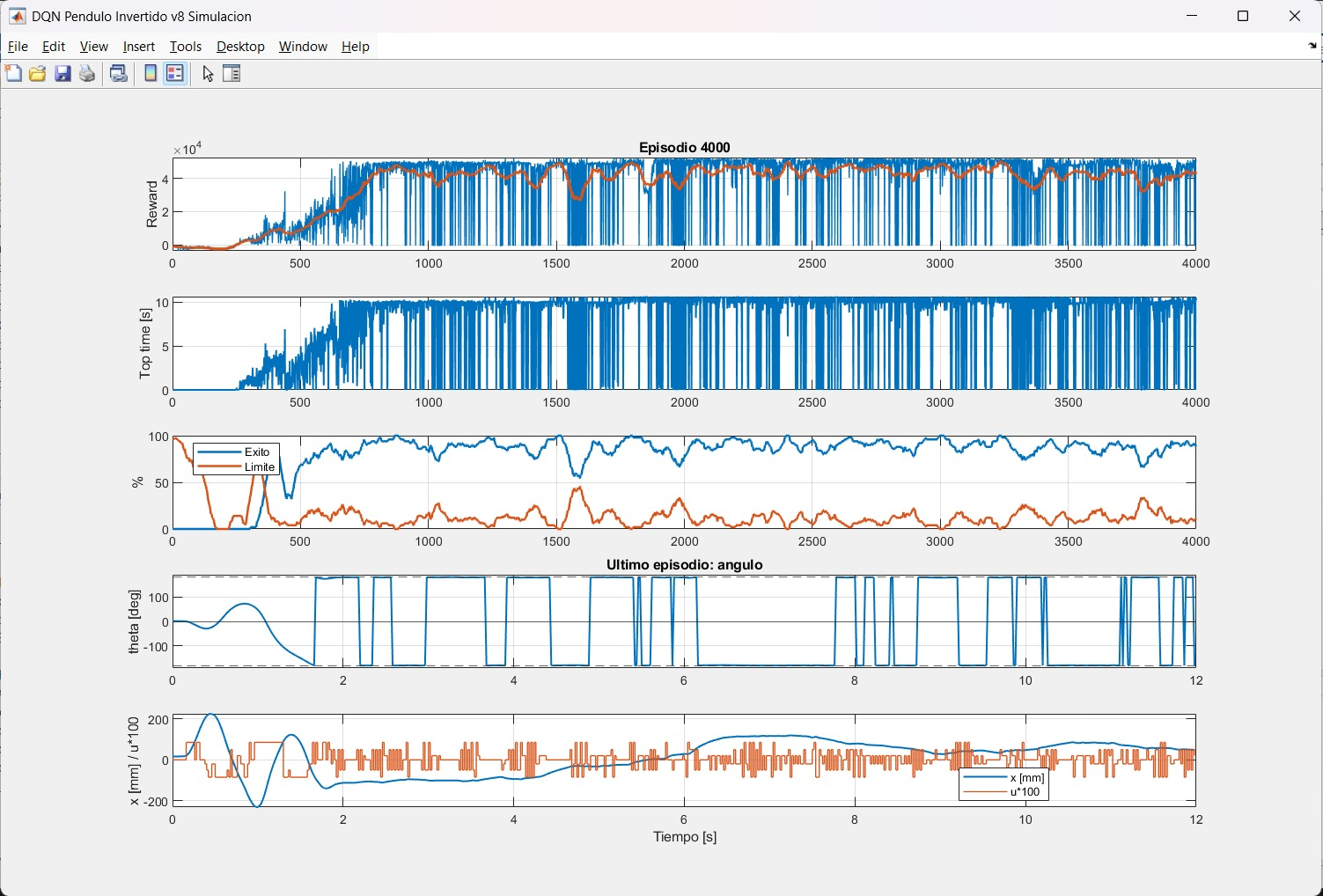
De arriba a abajo: reward por episodio con promedio móvil (naranja), tiempo en equilibrio por episodio, tasa de éxito vs. límite de posición, ángulo θ del último episodio, y posición x junto con esfuerzo de control u.
Métricas Finales (últimos 50 episodios)

| Métrica | Valor |
|---|---|
| Reward medio | 42,877.5 |
| Reward máximo | 51,577.8 |
| Pasos promedio por episodio | 545.6 / 600 |
| Tasa de éxito | 90 % |
| Tasa de límite de posición | 10 % |
| Tiempo en equilibrio (promedio) | 9.02 s |
| Tiempo en equilibrio (máximo) | 10.60 s |
Prueba de Política Greedy Final
Al aplicar la política greedy (ε = 0) sobre un episodio completo de prueba en el hardware físico:
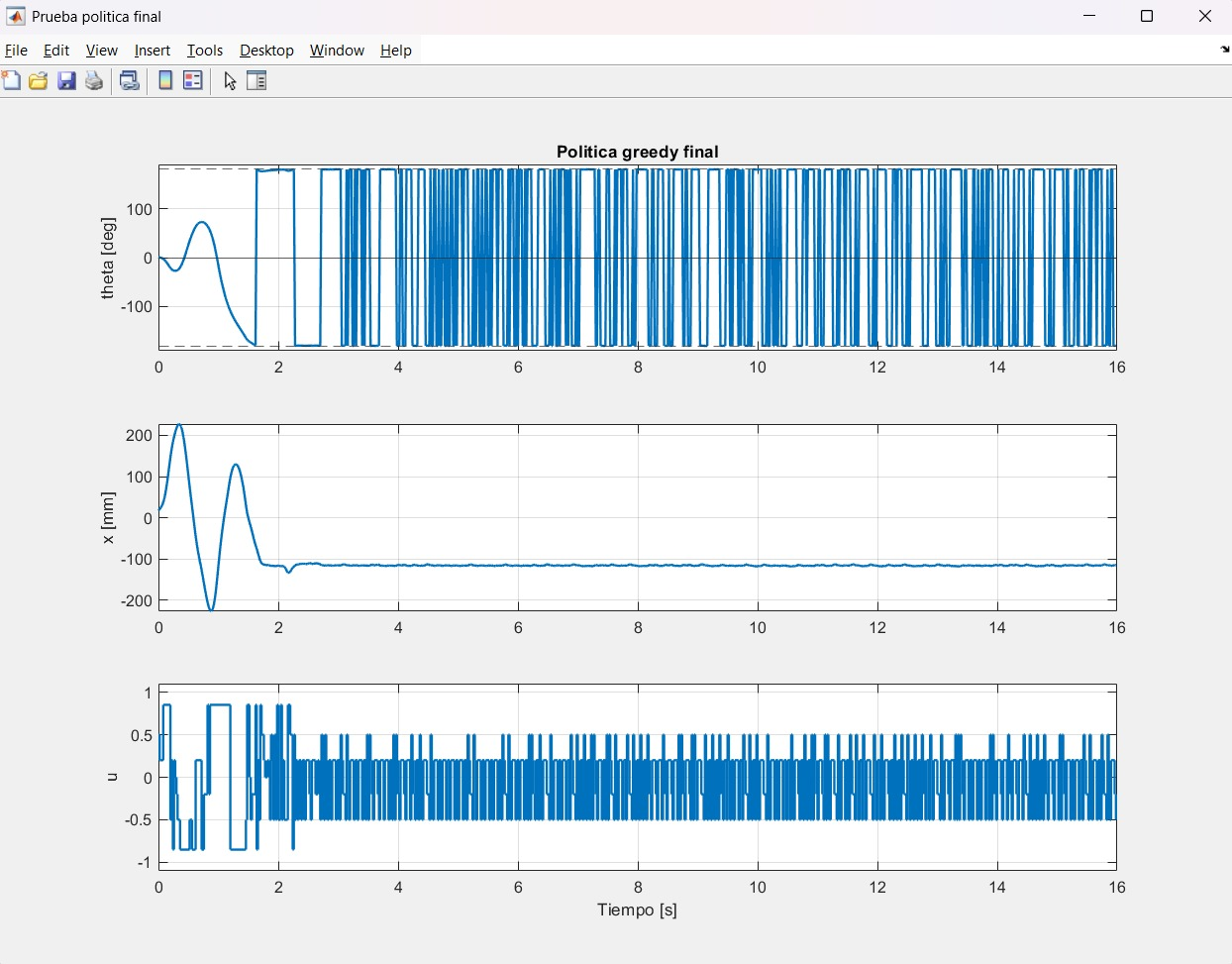
Gráfica de la prueba greedy en hardware: ángulo θ (arriba), posición del carro x (centro) y esfuerzo de control u (abajo) a lo largo de 16 segundos.
| Métrica | Valor |
|---|---|
| Tiempo acumulado arriba | 14.56 s |
| Reward total de prueba | 71,157.5 |
El agente mantuvo el péndulo en equilibrio superior durante 14.56 segundos acumulados en la prueba greedy, superando ampliamente el umbral de éxito de 10 s.
Análisis de las Gráficas
Entrenamiento (4,000 episodios)
- Reward por episodio — converge a ~40,000–50,000 con varianza residual. La línea naranja (promedio móvil) confirma la tendencia ascendente.
- Top time — el tiempo en equilibrio crece consistentemente hasta saturar en 10 s (límite del episodio).
- Tasa de éxito / límite — éxito (azul) converge cerca del 80–90 %; límites de posición (naranja) se mantienen bajos.
- Ángulo θ (último episodio) — el péndulo se estabiliza en θ ≈ 0° y el controlador lo mantiene frente a perturbaciones.
- Posición x y esfuerzo u — el carro converge a una posición lateral con esfuerzo de control moderado.
Política Greedy en Hardware
- θ oscila con alta frecuencia (chattering visible), indicando que la política discreta aplica acciones de signo opuesto rápidamente para mantenerse en el punto de equilibrio. Esto es esperable con 41 acciones discretas.
- x converge a ~−120 mm desde el centro y permanece estable, lo que indica que el carro encontró una posición de trabajo sin llegar al límite.
- u es una señal de alta frecuencia de baja amplitud (~±0.3), coherente con un controlador activo en régimen de equilibrio.
Presentaciones
Día de las Ingenierías IBERO — 5 de mayo de 2026
Presentación del prototipo físico y demostración en vivo del equilibrio DQN ante jurado y comunidad universitaria.
Congreso ITESO Guadalajara 2026 — 26–28 de mayo de 2026
Presentación académica del proyecto ante la comunidad de ingeniería a nivel nacional, cubriendo la metodología Sim-to-Real, la comparativa Shallow vs. DQN y los resultados experimentales.